เมื่อพูดถึง AI ที่เป็น ?Neural network (เครือข่ายประสาทเทียม)? ที่เอาไว้ใช้สร้างรูปภาพขึ้นมาให้นั้น ก็สามารถทำได้หลายวิธี หรือหลายโมเดล ดังตัวอย่างต่อไปนี้ ?ที่ผมเรียบเรียงมาให้
ความต้องการขั้นต่ำ
- ให้ติดตั้ง Anaconda มันเป็นแพลตฟอร์มเอาไว้เขียนภาษา Python ซึ่งถ้าลง Anaconda ตัวเดียว ก็จะได้คอมไพเลอร์ของ Python รวมทั้งโมดูลเสริม ต่างๆ สำหรับงาน AI เช่น?Numpy, ?Matplotlib,?scipy
- ติดตั้ง TensorFlow (ไลบรารี่สำหรับ DeepLearning) ด้วยคำสั่ง
pip install tensorflow
ตัวอย่างที่ 1 ฝึก AI สร้างรูปเลียนแบบต้นฉบับ
เรามาดูตัวอย่างใช้ AI วาดภาพเลียนแบบต้นฉบับอย่างง่ายๆ กันก่อนดีไหม
แรงบันดาลใจมาจาก ?http://cs.stanford.edu/people/karpathy/convnetjs/demo/image_regression.html
อันนี้ใช้ภาษาจาวาสคริปต์ ด้วยไลบรารี่ ConvNet.js
ถ้าไปที่เว็บต้นทางที่บอก ก็สามารถวาดรูปแมวเหมียวจากต้นฉบับได้ ดังรูปข้างล่าง

ภาพซ้ายคือแมวต้นฉบับ ส่วนขวาคือ Neural network ธรรมดา ที่พยายามหัดวาดรูปแมวเหมียว ?แต่ยังไม่เก่งเท่าไร
คราวนี้ผมจะทำเลียนแบบบ้าง แต่ใช้ภาษา Python นะ
โดยใช้โมเดลคณิตที่เป็น Neural network ซึ่งมีเลเยอร์ที่เป็น Hidden ทั้งหมด 7 ชั้น?ดังตาราง
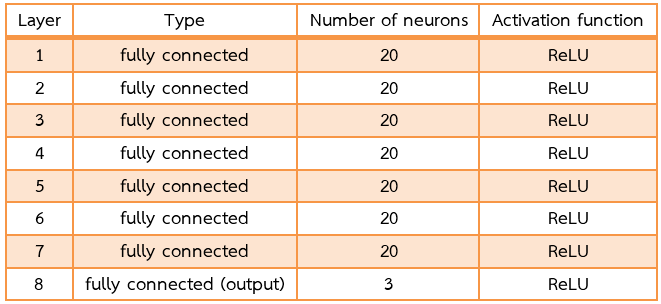
เรื่องโครงสร้าง neural network ข้างใน ไม่ต้องคิดอะไรมาก?ให้คิดว่ามันเป็นกล่องดำ ที่มี input เข้าไป แล้วได้ output ออกมา
เลเยอร์ที่เป็น Input
เลเยอร์ input มีขนาด 2 ใช้ตำแหน่งจุด x,y บนรูปภาพ เป็น input เข้าสู่โมเดล ?ดังรูป
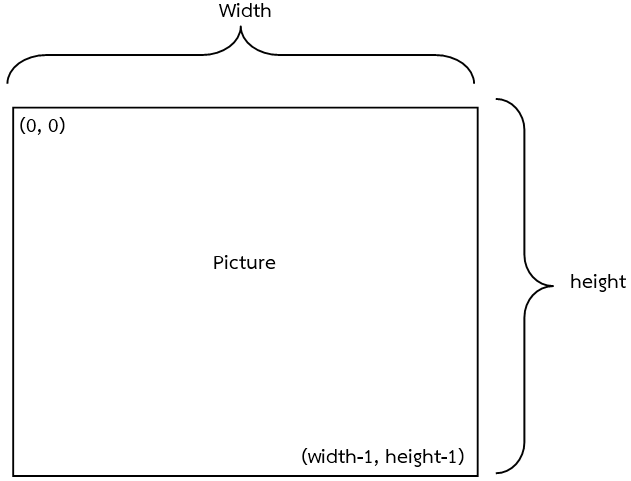
ในภาษา Python ขนาดรูปภาพจะเป็น height x width (สูง x กว้าง ไม่ใช่ กว้าง x สูง)
เลเยอร์ที่เป็น Output
เลเยอร์ Output มีขนาด 3 (ค่าสี Red, Green, Blue)
(Output เป็น regression ไม่มี Activation function แต่อย่างใด)
เมื่อมี 1 input เป็นตำแหน่งจุด x, y บนรูปภาพ เข้าสู่โมเดล ก็จะได้ค่าสีรูปภาพ 3 ค่าได้แก่ ?R, G, B ต่อ 1 pixel ?สอดคล้องกับตำแหน่ง x, y ?บนรูปนั้นๆ

แต่เวลา Input เข้าไปในโมเดล ก็จะใช้ตำแหน่งจุด x, y บนรูปภาพทั้งหมด

ซอร์สโค้ดที่ใช้รัน
ผมทำไว้เล่นๆ 2 เวอร์ชั่น ได้แก่ keras กับ tensorflow ดังลิงค์ต่อไปนี้
https://github.com/adminho/machine-learning/blob/master/Art_example/paint_keras.py
https://github.com/adminho/machine-learning/blob/master/Art_example/paint_tensorflow.py
?
ภาพซ้ายมือด้านบน เป็นไก่บ้านผม 2 ตัว ส่วนด้านขวามือเป็นผลงาน AI ที่กำลังวาดภาพเลียนแบบทางซ้ายมือ
แต่ความสามารถของ AI ยังวาดรูปได้กากๆ 555++
อ้างอิง
[1] ?http://cs.stanford.edu/people/karpathy/convnetjs/demo/image_regression.html
ตัวอย่างที่ 2 Fast PixelCNN++
จะพูดถึงโมเดล AI ที่ชื่อ Fast PixelCNN++ เอาไว้สร้างรูปอัตโนมัติ ?เพื่อเอาไปประยุกต์ใช้ในงานวิจัยอื่น โดยเฉพาะเรื่อง Computer vision (ไม่ได้เอามาวาดรูปแข่งกับคน หรือจะทำก็ได้นะ ไม่เป็นไร) เนื้อหาอ้างอิงจาก paper ชื่อ Fast Generation for Convolutional Autoregressive Models
PixelCNN
ขอเท้าความถึงโมเดล Neural Network ที่ชื่อ PixelCNN คอนเซปต์จะพล็อตรูปภาพทีละหนึ่ง Pixel อัตโนมัติ โดยอาศัยข้อมูล Pixel ก่อนหน้านี้
ตัวอย่างผลงานที่ใช้ PixelCNN ได้แก่ Pixel Recursive Super Resolution ดังรูปข้างล่าง
- Paper นี้จะใช้โมเดล PixelCNN กู้รูปภาพจากความละเอียดต่ำๆ ให้กลับมาคมชัดขึ้น
- โดยฝั่งซ้ายมือเป็นภาพที่มีความละเอียดต่ำมองไม่เห็นอะไร (ขนาด 8×8)
- ส่วนภาพตรงกลาง เป็นการใช้ PixelCNN ไปกู้คืนมาให้ชัดขึ้น (ขนาด 32 x 32) เมื่อเปรียบเทียบกับภาพจริงฝั่งขวามือ
?ทำความรู้จักกับ PixelCNN ?สักนิด
- โดยเริ่มต้น PixelCNN พัฒนาโดย DeepMind ของ Google
- PixelCNN เป็นโมเดลประเภท ?Generative model? แปลเป็นไทยตรงตัว ก็คือโมเดลให้กำเนิด? (ในที่นี้คือ ให้กำเนิดรูปภาพ)
- ถ้าจะเรียกจำเพาะเจาะจงอีก ก็บอกว่า PixelCNN ?เป็นโมเดลประเภท autoregressive model (ถ้างงขอโทษด้วย)
ข้อเสียของ PixelCNN
หนึ่งในหายนะของโมเดลแบบ PixelCNN มันทำงานโคตรช้า เมื่อเปรียบเทียบกับโมเดลอื่นที่ใช้สร้างรูป ที่สามารถสร้างรูปได้ทีเดียวทั้งภาพ (ไม่พล็อตทีละจุดเหมือน PixelCNN) ตัวอย่าง เช่น?Generative Adversarial Networks และ Variational Autoencoders
เพราะความช้าเป็นเหตุ ด้วยเหตุนี้ OpenAI จึงมาปรับปรุงประสิทธิภาพ โดยตั้งชื่อโมเดลใหม่เป็น PixelCNN++
ต่อมาทีมวิจัย OpenAI อีกนั้นแหละ ก็เอา PixelCNN++ มาพัฒนาต่อ เพิ่มความเร็วในการสร้างภาพ โดยตั้งชื่อวิธีการใหม่เป็น Fast PixelCNN++ ?ซึ่งก็คือสิ่งที่บทความนี้กำลังกล่าวถึงนั้นเอง
คอนเซปต์โดยย่อของ Fast PixelCNN++ จะประมาณนี้
- Fast PixelCNN++ ก็คือประเภท generative model (แต่เป็น autoregressive model)
- คอนเซปต์การทำงานเดียวกับ PixelCNN แบบดั้งเดิม เอาไว้สร้างรูปทีละ pixel จากข้อมูล pixel ก่อนหน้า
ซึ่งใน Fast PixelCNN++ มันจะดู pixel ที่ 0 ถึง 9 ของรูปภาพก่อนหน้านี้ แล้วนำมาสร้าง pixel ที่ 10
จากนั้นมันก็ขยับมาดู pixel ที่ 1 ถึง 10 ในรูปภาพก่อนหน้านี้? แล้วสร้าง pixel ที่ 11
?ทำแบบนี้ไปเรื่อยๆ จนได้ภาพสมบูรณ์
จริงๆ มันมีรายละเอียดมากกว่านี้นะ ถ้าสนใจก็ลองดูเพิ่มที่นี้ [1]

ภาพซ้ายคืออัลกอริทึมแบบเก่าที่ช้า เมื่อเปรียบเทียบกับวิธีการใหม่ของ Fast PixelCNN++ ที่เร็วกว่า
ความต้องการขึ้นต่ำ
- ติดตั้ง ?Numpy, ?Matplotlib
- ติดตั้ง TensorFlow
ซอร์สโค้ดที่ใช้รัน
ให้ไปที่ https://github.com/PrajitR/fast-pixel-cnn?เพื่อดาวน์โหลดซอร์สโค้ดโปรเจค หรือจะใช้ git ดาวน์โหลดมาก็ได้ ด้วยคำสั่งนี้
git clone https://github.com/PrajitR/fast-pixel-cnn.git
Datasets
ให้ไปที่?http://alpha.openai.com/pxpp.zip เพื่อดาวน์โหลดไฟล์ zip แล้วแตกไฟล์ออกมาเป็น params_cifar.ckpt มันคือไฟล์โมเดล AI (ถูกเทรนมาให้เรียบร้อยแล้ว)
โครงสร้างโปรเจค (เฉพาะไฟล์ที่สำคัญ)
root_folder/
|--fast_pixel_cnn_pp/
|--images/
|---
|--generate.py
|--params_cifar.ckpt
generate.py ?คือโค้ดหลัก ?ส่วน images อันนี้คือโฟลเดอร์ ที่ผมสร้างขึ้นมาเอง สำหรับเก็บไฟล์รูปที่จะถูกสร้างขึ้นมา
วิธีการรันก็ให้ใช้คำสั่งดังตัวอย่าง
python generate.py --checkpoint=/path/to/params_cifar.ckpt --save_dir=/path/to/save/generated/images
อย่างผมรันจริงก็ต้องใช้คำสั่ง
python generate.py --checkpoint=params_cifar.ckpt --save_dir=images
โดยดีฟอลต์เมื่อรันเสร็จ จะสร้างรูปภาพ ขนาด 32×32 จำนวน 16 รูปในเฟรมเดียว ?ดังวีดีโอข้างล่าง
ซึ่งโค้ดจะวนสร้างรูปภาพไปเรื่อยๆ ชั่วนาตาปี (จนกว่าเราจะกดยกเลิก Control-C) อย่างของผมก็จะเก็บรูปที่สร้างไว้แล้วที่โฟลเดอร์ images
อ้างอิง
[1] https://github.com/PrajitR/fast-pixel-cnn
[2] https://arxiv.org/abs/1704.06001
ตัวอย่างที่ 3 สร้างใบหน้าคน
โปรเจคนี้เอาไว้สร้างภาพหน้าคนอย่างอัตโนมัติโดยใช้ AI ดังรูปข้างล่าง
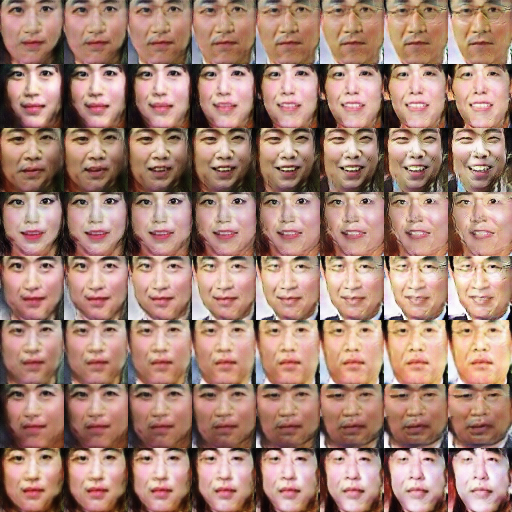
สามารถดูตัวอย่างเป็นวีดีโอได้ที่?http://carpedm20.github.io/faces/
โครงสร้าง Neural network
เมื่อพูดถึงโครงสร้างจะใช้? Deep Convolutional Generative Adversarial Networks?(DCGAN)
โดยที่ตัว Generative model กับ Generative model จะใช้ CNN (Convolutional neural network)
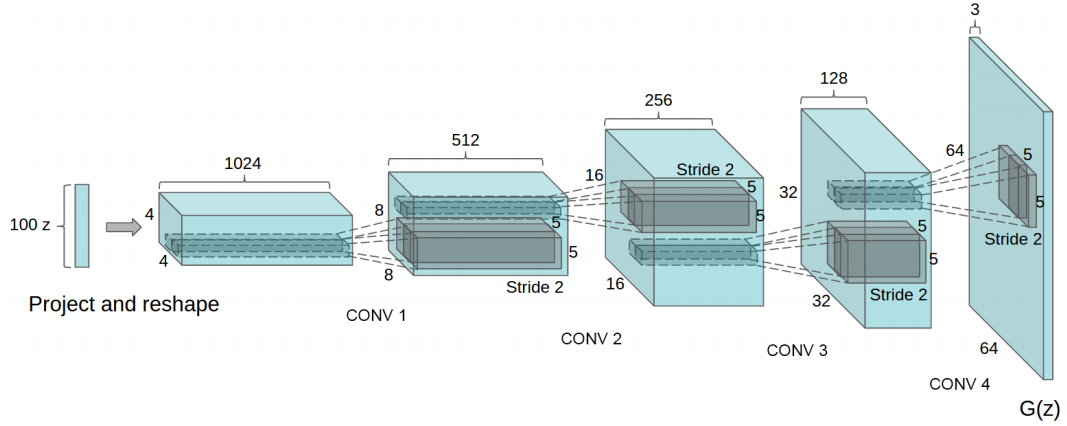
ความต้องการขั้นต่ำ
- Python 2.7 or Python 3.3+
- Tensorflow 0.12.1
- SciPy
- pillow
- (อ็อปชั่นเสริมl)?moviepy?(for visualization)
- (อ็อปชั่นเสริม)?Align&Cropped Images.zip?: Large-scale CelebFaces Dataset
?ซอร์สโค้ดที่ใช้รัน
ไปที่ https://github.com/carpedm20/DCGAN-tensorflow เพื่อดาวน์โหลดซอร์สโค้ดโปรเจค หรือจะใช้ git ดาวน์โหลดมาก็ได้ ด้วยคำสั่งนี้
git clone?https://github.com/carpedm20/DCGAN-tensorflow.git
แต่ทั้งนี้ต้องติดตั้งโมดูลเสริม
python install tqdm
โครงสร้างโปรเจค (เฉพาะไฟล์ที่สำคัญ)
root_folder/
|-- data/
|--celebA/
|--mnist/
|--checkpoint/
|--download.py
|--main.py
|--model.py
Datasets
ให้ใช้คำสั่งดังนี้
python download.py mnist celebA
ทว่าผมพบว่ามีบั๊กอยู่ในไฟล์ download.py
…สำหรับ Dataset ?ที่ชื่อ celebA ดาวน์โหลดได้ไม่มีปัญหาอะไร
…แต่ Dataset ที่ชื่อ mnist ดันดาวน์โหลดไม่ได้นี้ซิ ผมเข้าใจว่าตัวเองรันอยู่บนวินโดวส์ จึงไม่มีคำสั่ง gzip ใช้แตกไฟล์ที่ดาวน์โหลดมา
ถ้าไปดูซอร์สโค้ download.py ในบรรทัดที่ 151-155 จะเห็นเขียนดังนี้
url_base = 'http://yann.lecun.com/exdb/mnist/' file_names = ['train-images-idx3-ubyte.gz', 'train-labels-idx1-ubyte.gz', 't10k-images-idx3-ubyte.gz', 't10k-labels-idx1-ubyte.gz']
จากซอร์สโค้ด จะเห็นชื่อ url กับชื่อไฟล์ .gz ?สำหรับดาวน์โหลด ซึ่งถ้ารันไฟล์ download.py ไม่ผ่าน ก็ใช้มือดาวน์โหลดเอง ตามลิงค์ข้างล่าง
- http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz
- http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz
- http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz
- http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz
จากนั้นก็ต้องแตกไฟล์ .gz ทุกตัวออกมาได้เป็น
t10k-images.idx3-ubyte t10k-labels.idx1-ubyte train-images.idx3-ubyte train-labels.idx1-ubyte
แต่ทั้งนี้ต้องแก้ชื่อไฟล์ ให้เป็นดังต่อไปนี้ (ในไฟล์ model.py จะมี error ชื่อไฟล์ เวลาโหลดข้อมูลใน Datasets ดังกล่าว)
t10k-images-idx3-ubyte t10k-labels-idx1-ubyte train-images-idx3-ubyte train-labels-idx1-ubyte
จากนั้นก็เซฟไฟล์ Datasets เหล่านี้ไว้ที่ data/mnist
คำสั่งรัน
เทรนโมเดลพร้อม Datasets ที่ดาวน์โหลดมา ดังตัวอย่าง
python main.py --dataset mnist --input_height=28 --output_height=28 --train python main.py --dataset celebA --input_height=108 --train --crop
หรือถ้าจะ test โมเดลก็ให้ใช้คำสั่งนี้
python main.py --dataset mnist --input_height=28 --output_height=28 python main.py --dataset celebA --input_height=108 --crop
อ้างอิง
[1]?https://github.com/carpedm20/DCGAN-tensorflow
ตัวอย่างที่ 4 แปลงชายเป็นหญิง หญิงเป็นชาย
โปรเจคนี้ชื่อ deep-makeover?จะใช้ AI ทำการแปลงหน้าชายให้กลายเป็นหญิง จากผู้หญิงเป็นผู้ชาย ดังรูปข้างล่าง


สองภาพข้างบนคือ ตัวอย่างแปลงหน้าจากชายเป็นหญิง และจากหญิงเป็นชาย ซึ่งใช่เวลาเทรนเพียง 2 ชั่วโมงบน ?GTX 1080 GPU อันเดียว
โครงสร้าง Neural Networks
- โครงสร้างภายในเป็น conditioned DCGAN
- โดยฝั่ง generator แบ่งออกเป็น 2 ส่วนได้แก่ encoder กับ decoder
- encoder รับ input เป็นภาพ แล้วเข้ารหัส (a lower-dimensional latent representation)
- decoder จะถอดรหัสจาก encoder เพื่อให้ได้เป็นภาพ RGB ที่มีขนาดเหมือนกับภาพ input
- ทั้งนี้ตัว generator กับ discriminator ก็ไปใช้โมเดลสำเร็จรูปอย่าง?ResNet อีกที
ความต้องการขั้นต่ำ
- Python 3.5+
- Tensorflow r0.12+
- และ numpy กับ scipy.
ซอร์สโค้ดที่ใช้รัน
ไปที่ https://github.com/david-gpu/deep-makeover เพื่อดาวน์โหลดซอร์สโค้ดโปรเจค หรือจะใช้ git ดาวน์โหลดมาก็ได้ ด้วยคำสั่งนี้
git clone https://github.com/david-gpu/deep-makeover.git
Datasets
ให้ไปดาวน์โหลด?Large-scale CelebFaces Attributes (CelebA) Dataset แล้วเลือก “Align&Cropped Images” แต่ให้ไปดาวน์โหลดที่?google drive นะ ?(DropBox เข้าไม่ได้)
หรือจะไปใข้ไฟล์ download.py ของตัวอย่างที่ 3 ก็ได้ ?เพื่อช่วยดาวน์โหลด Datasets (ใช้เหมือนกัน)?อย่างของผมเก็บ Datasets ไว้ที่
D:\MyProject\python\DCGAN\DCGAN-tensorflow\data\celebA
แต่ทั้งนี้ต้องดาวน์โหลด list_attr_celeba.txt ด้วย?แล้วเซฟไว้ที่เดียวกับ Datasets เดียวกัน (อย่างของผมคือ?D:\MyProject\python\DCGAN\DCGAN-tensorflow\data\celebA)
คำสั่งรัน
เวลารันก็ต้องระบุ Datasets ไว้ด้วย ดังตัวอย่าง
python dm_main.py --run train --dataset "D:\MyProject\python\DCGAN\DCGAN-tensorflow\data\celebA"
อ้างอิง
[1] ?https://github.com/david-gpu/deep-makeover
ตัวอย่างที่ 5 สร้างรูปด้วยความละเอียดสูง
รูปที่เห็นในคลิปไม่ใช่คนจริงๆ
แต่เป็นรูปที่เกิดจากปัญญาประดิษฐ์ (AI) สร้างขึ้นมา
ด้วยความละเอียดสูง
จากโปรเจค StyleGAN ซึ่งเป็นผลงานวิจัยของบริษัท NVIDIA
.
จริงไม่ใช้แค่สร้างรูปคนขึ้นมาอย่างเดียวนะ
AI สามารถสร้างรูปหมา แมว รถ ก็สร้างได้
.
แต่การสอนโมเดล AI ให้ฉลาด ก่อนนำไปใช้งานจริงนั้น
ค่อยข้างใช้เวลาสอนนาน รันข้ามวันเลยที่เดียว
อ่านได้ที่ https://arxiv.org/abs/1812.04948
.
ตัวอย่างโค้ดเอาไว้ใช้รันก็ที่ลิงค์นี้
https://github.com/NVlabs/stylegan/
เครื่องควรมี NVIDIA GPUs ถึงจะเหมาะกับการรัน
รันได้ทั้งลีนุกซ์กับวินโดวส์ แต่เขาแนะนำลีนุกซ์ดีกว่า
บทความ AI อื่นๆ ที่น่าสนใจ
- วิชาเลขตอนม.ปลาย นำไปใช้ในวิชาคอมขั้นสูงอะไรบ้าง?
- ใช้ AI เขียนหนังสือเอง ซึ่งอาจถูกนำไปใช้ในทางที่ผิดได้
- เห็นหน้าคนปุ๊บก็รู้ว่าชื่ออะไร ด้วยเทคโนโลยีจดจำใบหน้า Face recognition
- ตรวจจับภาพลามก อนาจาร ด้วยความแม่นยำสูงเวอร์ ด้วย AI
- สุดล้ำใช้ AI แต่งดนตรี
- รู้จำเสียงพูด Speech Recognition ด้วย JavaScript ง่ายนิดเดียว
- ใช้ AI เล่มเกมอัตโนมัติ
- ใช้ AI ตรวจจับการเคลื่อนไหวของมนุษย์แบบเรียลไทม์
- ใช้ AI ตรวจจับใบหน้า อารมณ์คน และเพศ
- ใช้ AI แปลงภาพขาวดำเป็นภาพสี
- ใช้ AI ลบภาพพื้นหลังออก
- ตรวจจับวัตถุในรูปภาพด้วยโค้ด AI แค่ 10 บรรทัด สู่การตรวจจับวัตถุแบบเรียลไทม์ และการทำ segmentation
- สร้าง Chat bots อย่างง่ายๆ ด้วย Python
- ตัดคำภาษาไทยโดยใช้ Deep learning (AI)
- ใช้ AI เขียนโค้ดอัตโนมัติ เพียงดูภาพหน้าจอ GUI ของโปรแกรม
- วิธีเขียนโค้ดดึงข้อมูลหุ้นไทย ด้วยภาษา Python (แจกโค้ดฟรี)
- ตัวอย่างใช้ AI เนรมิตรูปภาพ
- เป็นไปได้ไหม? ที่ AI จะมาเขียนโปรแกรมแทนโปรแกรมเมอร์
เขียนโดย แอดมินโฮ โอน้อยออก